LinearRegression : 선형 회귀 모델을 만드는 scikit-learn 클래스
KNeighborsRegressor : KNN 회귀 모델을 만드는 scikit-learn 클래스
** numpy reshape : 배열의 크기를 바꿀 때 사용하는 method, 원본 배열에 있는 원소의 개수를 맞춰야함
test_array=np.array([1,2,3,4])
test_array=test_array.reshape(2,2) #(4,) --> (2,2)
$R^2 = 1 - (타깃-예측)^2/(타깃-평균)^2$
from sklearn.metrics import mean_absolute_error
test_prediction = knr.predict(test_input)
mae = mean_absolute_error(test_target, test_prediction)
LinearRegression : 선형 회귀 모델을 만드는 scikit-learn 클래스
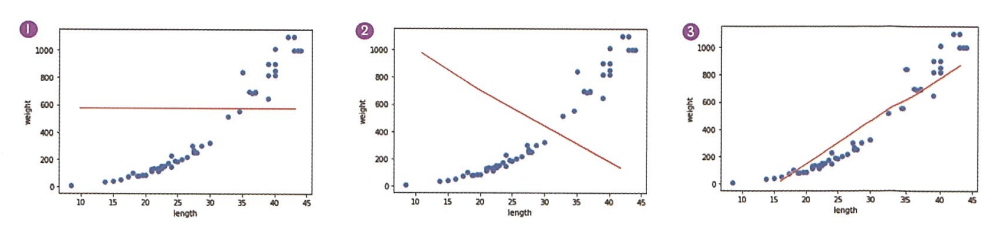
그래프 1. 데이터를 하나로 예측 -> 직선의 위치가 훈련 세트의 평균이라면 $R^2=0$ 그래프 2. 완전히 반대로 예측 -> $R^2<0$ 그래프 3. 가장 잘 예측한 직선 -> $R^2$이 1에 가까운 값
print(lr.coef_, lr.intercept_) # 기울기(특성의 계수)와 절편 확인